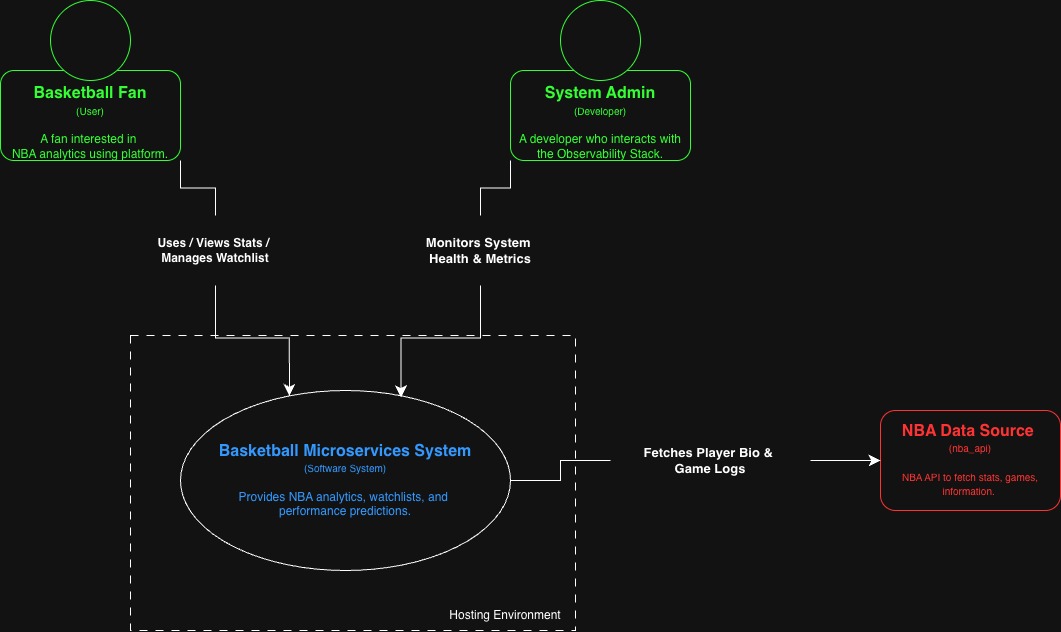
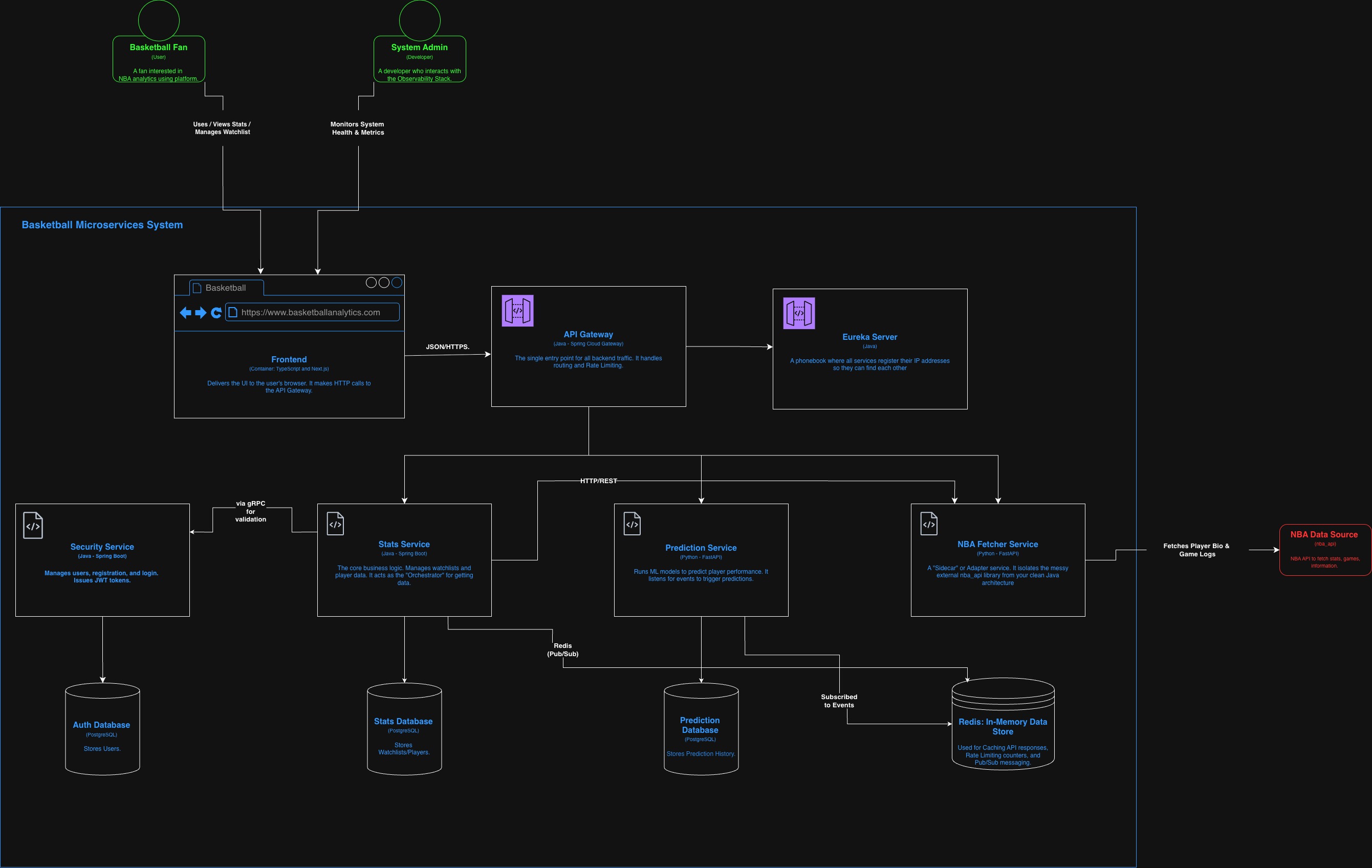
First Website
Sunkist Dental was my first real introduction to web development with real users in
mind. Before writing any
code, I spent time understanding the clinic’s patient base. Most patients were older
adults who preferred
calling the front desk to schedule appointments, which highlighted the first major
pain point:
- Pain Point #1: How to make online booking intuitive and comfortable for a
less tech-savvy audience.
The second issue was information inconsistency. Because the clinic was small,
business hours and service details
weren’t regularly updated on Google or Apple Maps. Patients often had to call just
to confirm basic information.
- Pain Point #2: Provide one central hub with up-to-date, reliable clinic
information.
So my task became clear: design a clean, friendly, and easy-to-use website that
allows patients to book
appointments online and view accurate clinic information without requiring the
staff to regularly maintain
it.
Through this project, I learned React.js, Firebase, EmailJS, version control, Figma,
and how to translate
real-world business constraints into product decisions. It was also my first deep
dive into frontend design, which was
rewarding, but it helped me realize that I’m more energized by logic, data flow, and
system architecture than
visual styling alone.
Measurable Impact: The online booking system reduced front desk workload by
~20% and contributed to
50+ new patient appointments, proving to me how software can directly improve
operations and revenue.
View this website in the Projects section.